定義
XPath即为XML路径语言 (XML Path Language),它是一种用来确定XML文档中某部分位置的语言。XPath基于XML的树状结构,提供在数据结构树中找寻**节点**的能力。
表示
简写后的语法
最简单的XPath如下:
/A/B/C
在这里选择所有符合规矩的C节点:C节点必须是B的子节点(B/C),同时B节点必须是A的子节点(A/B),而A是这个XML文档的根节点(/A)。此时的这种描述法类似于磁盘中文件的路径(URI),从盘符开始顺着一级一级的目录最终找到文件。
轴描述语法
| 坐标 | 名称 | 说明 | 缩写语法 |
|---|---|---|---|
| child | 子节点 | 比自身节点深度大的一层的节点,且被包含在自身之内 | 默认,不需要 |
| attribute | 属性 | @ | |
| descendant | 子孙节点 | 比自身节点深度大的节点,且被包含在自身之内 | 不提供 |
| descendant-or-self | 自身引用及子孙节点 | // | |
| parent | 父节点 | 比自身节点深度小一层的节点,且包含自身 | .. |
| ancestor | 祖先节点 | 比自身节点深度小的节点,且包含自身 | 不提供 |
| ancestor-or-self | 自身引用及祖先节点 | 不提供 | |
| following | 下文节点 | 按纵轴视图,在此节点后的所有完整节点,即不包含其祖先节点 | 不提供 |
| preceding | 前文节点 | 按纵轴视图,在此节点前的所有完整节点,即不包含其子孙节点 | 不提供 |
| following-sibling | 下一个同级节点 | 不提供 | |
| preceding-sibling | 上一个同级节点 | 不提供 | |
| self | 自己 | . | |
| namespace | 名称空间 | 不提供 |
节点描述
节点描述为一个逻辑真假表达式,任何真假判断表达式都可在节点后方括号里表示,这条件必须在XPath处理这个节点前先被满足。在某一步骤可有多少个描述并没有限制。
范例如下:
//a[@href='help.php']
这将检查元素a有没有href属性,并且该它的值是help.php。
复杂一些的范例如下:
//a[@href='help.php'][../div/@class='header']/@target
或
//a[@href='help.php'][name(..)='div'][../@class='header']/@target
此例将会选择符合条件的元素a的target属性。 要求元素a:
- 具有属性href且值为help.php
- 并且元素a具有父元素div
- 并且父元素(div)其自身具备class属性,值为header
實例講解
<?xml version="1.0" encoding="UTF-8"?>
<XPath>
<Title>An explanation of XPath in SDL Trados Studio</Title>
</XPath>该文件中有一名为<title>的待翻译元素。如果我创建一个新文件类型来提取该文本,我会导入该 XML 文件并设置以下解析规则:
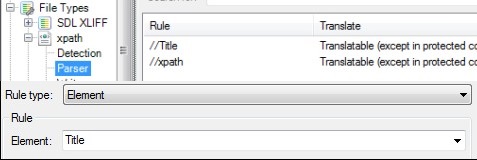
<?xml version="1.0" encoding="UTF-8"?>
<XPath>
<Book lang="en-US">
<Title>An explanation of XPath in SDL Trados Studio</Title>
<Text>XPath helps to <b>navigate</b> through the file.</Text>
<Text>It helps you pick out important <bn>brand names</bn></Text>
<Notes>
<Text>This should not be extracted.</Text>
</Notes>
</Book>
</XPath>所以,如果我想使用 XPath 创建规则, 把<text>元素提取出来,就应该做成以下这样:
//Text
但是,这种做法同时会提取所有<text>元素,甚至包括<note>元素中的<text元素,这并非我所需要的。所以我需要一个更具体的规则:
//Book/Text
这样,<note>元素里的text>元素就不会被提取出来了,即使它们名称相同也没有关系。
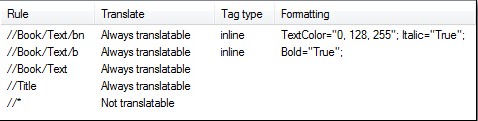
在这个例子中,我想对<bn>和<b> 元素添加类似的规则,并把它们设为内嵌标签,这样句子就不会被拆分。 然后我会再使用通配符添加一条规则:在没有规则明确告知的情况下不提取任何元素。
XPath 语言把星号诠释为“选择一切”因此,我添加了这样一条“非翻译”规则:
//*
把除此之外的其他所有部分都设定为始终翻译
我将得到这样一组规则(我也可以对这些规则运用一些简单的格式):
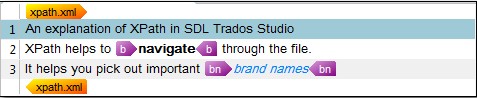
当我在 Studio 中打开该文档时,显示如下:
如果该文件的翻译文本在元素的属性上又该怎么做呢?
<?xml version="1.0" encoding="UTF-8"?>
<XPath>
<Book lang="en-US">
<Title mytitle="An explanation of XPath in SDL Trados Studio" />
<Text>XPath helps to <b>navigate</b> through the file.</Text>
<Text>It helps you pick out important <bn>brand names</bn></Text>
<Notes>
<Text>This should not be extracted.</Text>
</Notes>
</Book>
</XPath>
如果将该文件导入到 Studio,然后手动添加规则,设置属性为可翻译,如下:
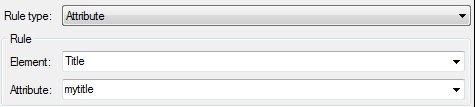
你就会再次在“规则”列中看到你所定义的 XPath 表达式:
//Title/@mytitle
更複雜的
<Text>Non-translatable <bn lock="y">brand names</bn> are locked</Text>
<Text>Translatable <bn lock="n">brand names</bn> are unlocked</Text>如果你希望这个名称一直显示,但又要确保译者保留该名称不变时,你要运用一条新的“不可翻译”规则来确认这一变化,这样一来,属性lock= 的值为“y”时该内容就会受到保护。此语法在方括号中对属性使用了一个引用而属性值放在引号中,显示如下:
//Book/Text/bn[@lock=”y”]
更更複雜的
<Text>These <bn lang="en-US" lock="y">brand names</bn> are locked</Text>
<Text>These <bn lang="en-US" lock="n">brand names</bn> are not</Text>
<Text>These <bn lang="de-DE" lock="y">brand names</bn> are locked</Text>
<Text>These <bn lang="de-DE" lock="n">brand names</bn> are not</Text>
<Text>These <bn lang="fr-FR" lock="y">brand names</bn> are locked</Text>
<Text>These <bn lang="fr-FR" lock="n">brand names</bn> are not</Text>想要准备多语言项目,运用为适当语言代码只提取文本的文件类型,你就可以添加一条与锁定内容类似的规则…..在仅提取法语翻译文本的基础上,使用自然语言查询把属性串在一起:
//Book/Text/bn[@lang=”fr-FR” and @lock=”y”]
现在, Studio 只从包含有 lang=“fr-FR” 属性的字符串中提取你所需的文本,并且如果 lock 的属性值为“y”,还会锁定相应内容。
更多延伸
//*[@translate=’yes’]
以这种方式翻译包含属性 translate 的任何元素的翻译内容,比如<BodyText translate=”yes”>,这个表达式可以用来提取所有翻译文本。
//A[@M = ‘8804’]/V
你需要<V>中的文本,但前提是父元素<A>中的M属性=”8804”。比如
<A M=“8804″><V>Beschreibung zum Task</V></A>使用由不同属性定义的元素属性翻译另一属性的内容。因此,翻译内容是 text属性,但前提是属性id=’journal1′
//journalItem[@id=’journal1′]/dialog/object/@text
检查两个相匹配的属性,然后继续查找后续元素。
//book[@lang=”fr-FR” and @translate=”y”]/ul/li
另類處理
拋棄 Regex,在XML文件的首末加上XPath代碼,即可簡便使用XPath方法。